crust / Part 13 - Summary
Marcel Braghetto 13 March 2022
A brief wrap up, a few thoughts and where to next.

A brief wrap up, a few thoughts and where to next.
In this article we will create a new Xcode project and implement the crust-build pipeline for building the iOS target platform. This will let us run crust on an iPhone - such that it could also be published to the Apple App Store - though you would need an active Apple Developer subscription to do that. We will:
crust-build as part of its build pipelinecrust-build project
In this article we will create a new Xcode project and implement the crust-build pipeline for building the MacOS Dekstop target platform. This will let us run crust as a bundled MacOS application - such that it could also be published to the Apple Mac App Store - though you would need an active Apple Developer subscription to do that. We will:
crust-build as part of its build pipelinecrust-build project
In this article we will implement the crust-build pipeline for building out the Android target platform. This will let us run crust on Android mobile devices. We will:
crust-build project to orchestrate the buildcrust-main source code with a few tweaks to make things run properly on mobile devices such as AndroidNote: Our
crust-buildimplementation for Android will be cross platform - meaning you will be able to do an Android target build on either Windows or MacOS.
In this article we will implement the crust-build pipeline for building out the Emscripten target platform. This gives us a web brower compatible version of crust - letting us run our application embedded in a web page! We will:
crust-build project to orchestrate the build steps to prepare and perform.crust-main source code to become Emscripten aware - there are a few things we have to do differently to run our main loop and know about the display size for Emscripten.Note: Our
crust-buildimplementation for Emscripten will be cross platform - meaning you will be able to do an Emscripten target build on either Windows or MacOS.
In this article we will implement the remainder of our OpenGL engine such that we can start rendering some 3D models in the main scene. The main tasks we need to complete are:
MeshData component into OpenGL mesh resourcesTextureData component into OpenGL texture resources
In this article we will implement the ability to load and store 3D models and resources for our scene. We will represent these resources in an abstracted way, avoiding the use of any vendor specific code such as OpenGL. This allows us to write our scene code in an agnostic fashion and describe 3D models and structures in a portable way.
Our engine implementation will be responsible for translating these abstractions into appropriate native resources - in our case OpenGL resources - though this could be other vendor technologies such as Vulkan.
In this article we will add a main loop to our application and display an OpenGL window. We will also stub out the basics for a scene with user input handling.
In this article we are going to write some of the core parts of crust-main which gets us to the point of being able to initialise the SDL system. We will focus our energy on Windows and MacOS, leaving the other target platforms for later once our main application code has matured, though we will sprinkle a tiny bit of forward thinking as we go to make later parts of the series easier.
We will also need to grow our crust-build application to download non Rust related dependencies and process them into our target platform build code.
In this article we will add enough code to our crust-build application to launch the crust-main application and debug it on Windows and MacOS Console.
In this article we will start filling in our crust-build project, writing the core set of utilities and data structures to support the build operations we’ll be performing and to stub out the skeleton for building each of our target platforms.
This also demonstrates how to create a Rust command line interface application (CLI) which could be a useful thing to know if you wanted to use Rust for authoring general command line tool systems applications.
In this article we are going to lay out the foundation structure for our Rust project and get to a stage where we can launch a basic version of our main application via Visual Studio Code on both MacOS and Windows.
Welcome to another research series! Toward the end of 2020 I wanted to learn something new again and was almost going to look into the latest version of C++ but something in the back of my brain reminded me of a programming language I’d heard of but didn’t know much about: Rust.
After a bit of basic research, Rust looked like it could be an interesting language to learn because it is designed for high performance but can also be compiled for many different platforms. The Rust language also seems to be picking up steam in popularity and usage in mainstream software and the language itself on the surface looked relatively pleasant to program in (compared to, say C/C++).
I decided to go for it and see what I could do with Rust - I chose to re-implement my older research project A Simple Triangle with Rust to see if I could build a cross platform code base that I could deploy on mobile phones as well as desktop machines.
We will refer to the Rust project in this series as crust (Cross platform Rust) because, it sounds kinda catchy and easy to remember and type!
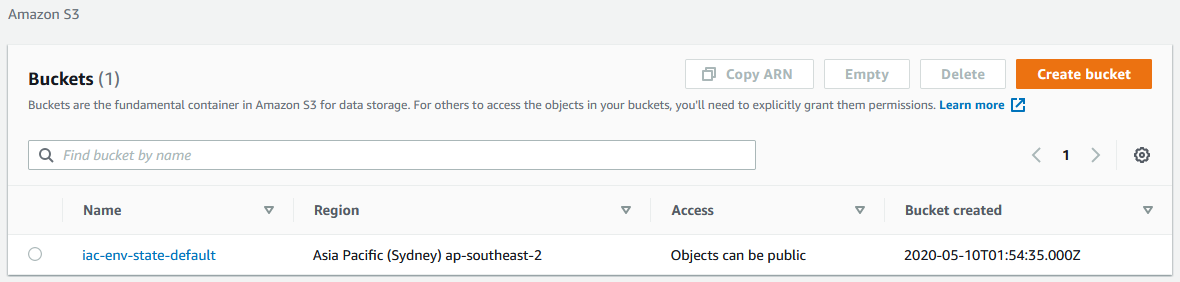
In this part we will take a small step forward with our automation and create an Amazon S3 bucket which we’ll use to store our Terraform state, using Terraform workspaces to help us. This will demonstrate how to orchestrate the testing and deployment of an AWS resource.

We are now ready to write ourselves a Jenkins build pipeline that will be triggered whenever a new Git branch is created or deleted, or a branch has had code changes applied to it.
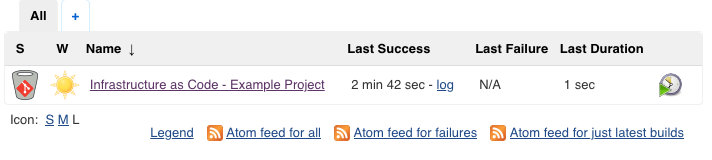
In this part we will setup a Jenkins instance using Docker to run it, and connect it to Bitbucket so it can automatically start build pipelines.
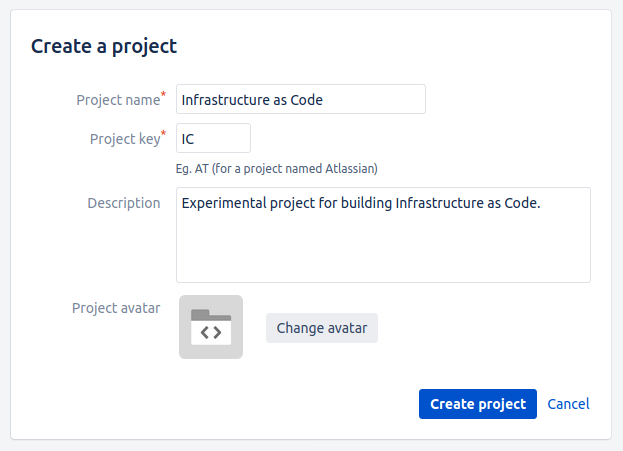
In this part we will setup a local instance of Bitbucket server using an evaluation license so we can push and pull code locally to test drive our build pipeline. It is fairly likely that you already use Bitbucket or Github or something like that to manage your Git repositories - the idea is the same as what we will be doing here so these instructions can be applied to whatever you are using though you’ll need to read the docs for your platform.
I picked Bitbucket server because I can run it easily on my localhost and it is just for experimentation purposes so I don’t mind deleting it when I’m done.
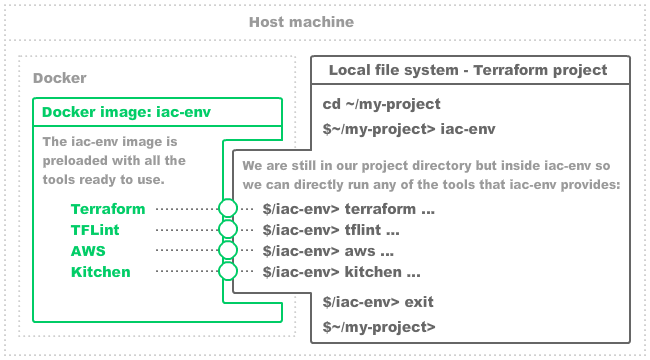
In this part we will get started with Docker and build our iac-env Docker image, which will be the star of the show! When we have our iac-env Docker image we can immediately start using it to run infrastructure as code tools. At a high level, our iac-env Docker image will do this for us:
Welcome to my learning adventure about infrastructure as code! At the time of authoring these articles I had just begun some work that required me to skill up a bit with Amazon Web Services and learn some tools that can assist with automation of provisioning cloud resources. All of this was very new to me and I started to experiment with tools and techniques to build up my knowledge - I figured I could write up my experience here and share the knowledge I’ve gathered. No doubt some of this stuff will seem very basic to those who have been in the profession for a while but we all gotta start somewhere!
In these articles I will explain the approach I took to create a self contained Docker image that acts as both a developer sandbox for writing cloud stuff locally, as well as being a build agent in a Jenkins build pipeline to perform the building, testing and deployment of cloud resources.

This will be the final technical article of the series where we will add some very basic user input to allow us to move around in our 3D scene with the keyboard. This article felt like a nice way to finish this series as our scene has been pretty static so far. The goals are:
In this article we will fix a bug related to resizing our window at runtime which causes our rendering to become incorrect.

It’s been a long road getting Vulkan up and running - on a few occasions I really had to force my motivation levels to complete some of the more tricky Vulkan articles though I’m glad I pushed through to this point. This article will reward us finally by seeing our 3D scene come to life in our Vulkan renderer.
We will:
render function properly in our Vulkan pipeline class including the provisioning of descriptor sets for our textures so they can be bound correctly to our pipeline layout.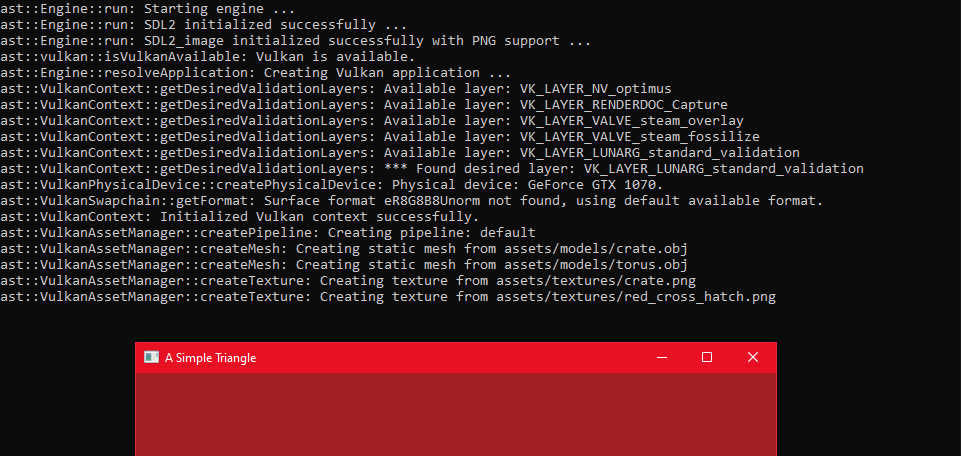
Now that loading mesh data is out of the way we can implement the final asset type for our Vulkan application - textures. There is actually no such thing as a built in ‘texture’ object in Vulkan, rather the expectation is that the developer implement a data structure that has the characteristics of a ‘texture’ that Vulkan can read from during rendering.
Specifically in this article we will:
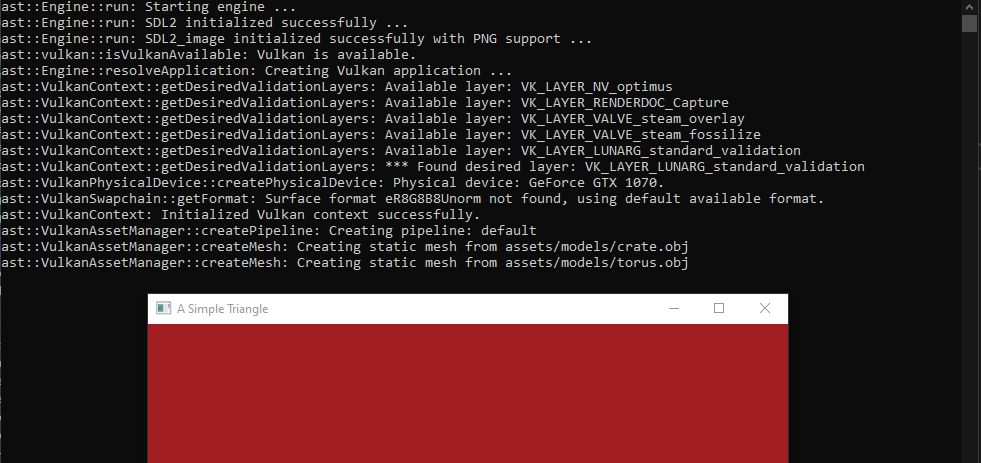
The next Vulkan implementation we will author is to load our static mesh asset files. To do this we will need to learn a bit about Vulkan buffers which are the data structures that will represent the vertices and indices of our mesh data inside Vulkan. We followed a similar approach in our OpenGL implementation where we took the basic mesh data from our ast::Mesh class and fed it into OpenGL specific buffers.
The (rather terse) Vulkan doco for buffers is here: https://www.khronos.org/registry/vulkan/specs/1.1-extensions/man/html/VkBuffer.html.
Specifically in this article we will:
The first category of asset integration for our Vulkan application will be the shader pipeline. You may remember when we wrote the OpenGL application we modelled a class named OpenGLPipeline whose responsibility was the following:
In this article we will implement an equivalent version of this pipeline for our Vulkan application. In particular we will:
We are finally ready to wire up our core Vulkan render loop, using a number of the Vulkan components we’ve worked so hard to implement.
The goal of this article is to:
We will start using a few new Vulkan components in this article as well, including semaphores and fences.
The (awesome) Vulkan Tutorial site has a great walkthrough of the key parts we will be implementing: https://vulkan-tutorial.com/Drawing_a_triangle/Drawing/Rendering_and_presentation and is worth a read especially to get familiar with semaphores and fences.
Some of our implementation will follow cues given in that tutorial site.
During our Vulkan render loop we will use our swapchain to cycle between its images - one of which will be presented while one or more are being prepared for the next time a frame is ready to be presented.
Our render pass will be the vehicle which will perform the rendering through the subpasses it contains. In order for a render pass to interact with the presentation it needs to use a collection of frame buffer attachments - one to complement each swapchain image.
Each time our render loop runs we will need to find out which swapchain image position to target, then associate the frame buffer at the same position from our collection of frame buffers with the render pass that will be invoked. This lets our render pass know where the output from its subpasses should go or be read from, syncing it to the correct swapchain image.
Warning: This will be a fairly complicated article - we will need to introduce a number of new Vulkan components which will require us to jump in and out of different parts of our code base as we go.
While the Vulkan swapchain was a difficult component to implement, it gives us the prequisites for some of the remaining components needed to form a renderer. In this article we will progress through the following topics:
In the previous article I mentioned that the swapchain is a Vulkan component which allows us to render to the screen and have off screen frame buffers that are cycled through, so the renderer can always be preparing the next frame while another is being presented. Creating an instance of a swapchain is a pretty dense coding exercise but we have little choice but to work our way through it as it is a prerequisite to rendering anything in Vulkan.
These sites provide some detailed explanations of the swapchain and ways to acquire one:
In the article about creating a physical device we wrote code to check for the support for the swapchain extension. We also requested the VK_KHR_SWAPCHAIN_EXTENSION_NAME extension when creating the logical device - so our application should be well positioned to successfully create a swapchain by the time we need one. That said, if we cannot create a swapchain it will trigger our fallback flow for our application - reverting to the OpenGL implementation.
Now that we have completed the setup for all of our platform targets to consume Vulkan the fun really begins! This article will revisit the initialisation code we wrote earlier that bootstraps Vulkan, adding in the following remaining components that Vulkan requires:
Before proceeding I’d highly recommend spending some time reviewing the following web sites to get familiar with some of these concepts - especially the Vulkan Tutorial site which taught me quite a lot about this:
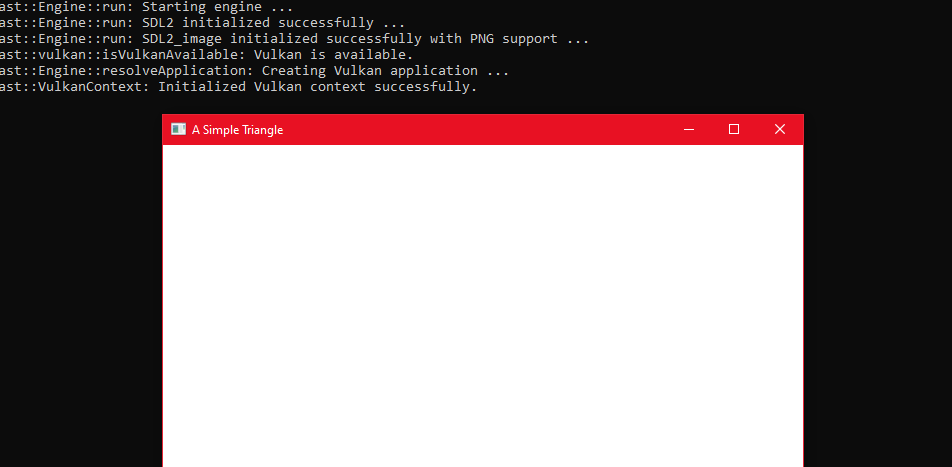
In this article we will configure our Windows platform to use Vulkan but keep our OpenGL implementation as a fallback at runtime. The Windows setup will be similar to earlier Windows articles where we included and linked against third party libraries such as SDL and GLM.
On a Windows computer a user will typically have graphics card drivers installed to provide the actual Vulkan implementation which we can’t link directly against. Instead we can use the .lib libraries which the Vulkan SDK provides us to give us a way to successfully link against the Vulkan APIs.

In this article we will update our C++ code base and Emscripten platform target configuration to exclude Vulkan as we can only run WebGL code in the browser. At the time of writing these articles there was no way to run Vulkan in the browser - though it appears it is front of mind for the development of next generation standard web standards.
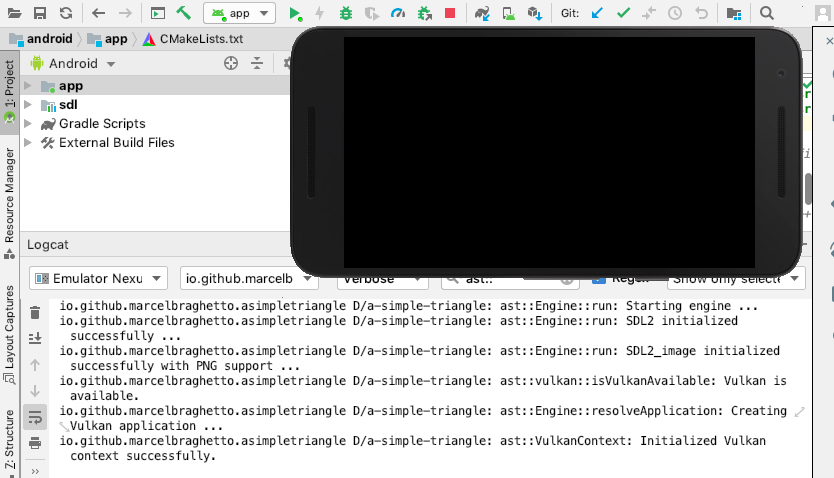
In this article we will get Vulkan running on Android. When I was researching how to do this I got stuck a number of times and went down a few rabbit holes trying to understand how to get the damn thing working the way I wanted.
One of the key differences with Android compared to MacOS and iOS is that we will use the dynamic Vulkan loader on Android - meaning that there will be no library that we link against at compile time to statically resolve the Vulkan APIs.
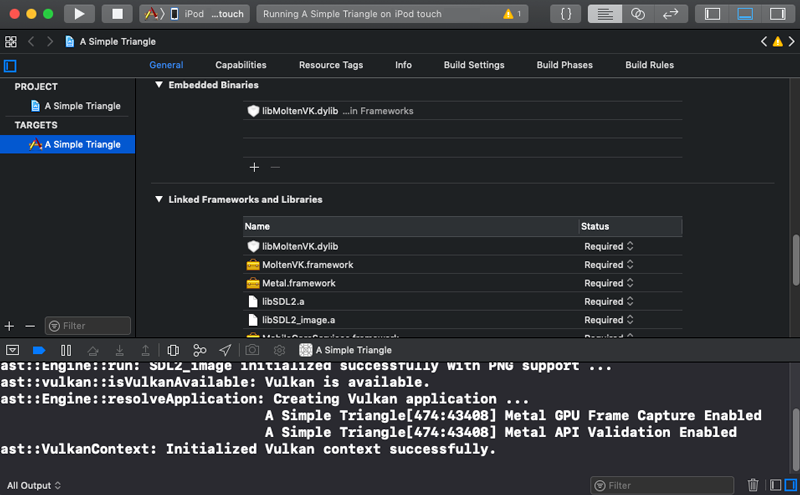
In this article we will get Vulkan running on iOS. This is a pivot point for our iOS platform target - in order to compile an iOS application to use Vulkan it will need to be capable of running Apple’s Metal framework.
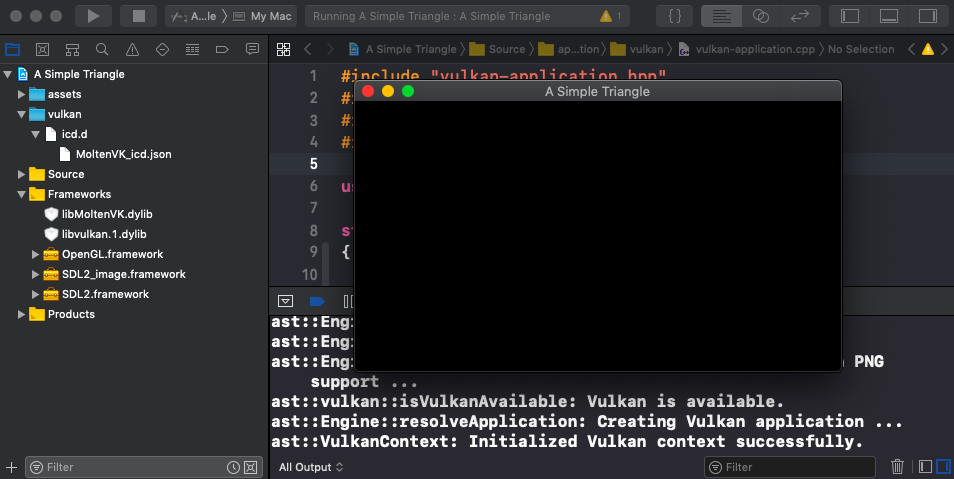
In this article we will take our basic Vulkan initialisation into the MacOS platform target. Most of the effort to do this is updating the Xcode project structure to include the correct libraries and files - most of the C++ is already done from the previous article.
Our Mac console will be the first target to setup Vulkan, though incidentally it will be via the MoltenVK library which gives us the ability to use the Vulkan SDK on Mac and iOS. In this article we will:
VulkanApplication class which will be a sibling to our existing OpenGLApplication class.Engine class to try and initialise Vulkan, and fall back to OpenGL if it cannot.![]()
Ok strap yourself in - now we start the journey of implementing our Vulkan rendering system. We will get Vulkan running on all of our target platforms that support it - which is pretty much everything except for Emscripten.
Before we get into the technical swing of things I would strongly recommend learning about Vulkan itself. This is the official site for the Vulkan APIs: https://www.khronos.org/vulkan/.
I had a lot of trouble understanding Vulkan and my fluency with it is still pretty basic. The way I was able to learn about it was from these awesome sites:
By working my way through some of the Vulkan tutorial sites and cross referencing demos in the Github links above, I was able to get Vulkan up and running successfully on my Mac and other platforms. One of the key outcomes I pushed for was to use the Vulkan C++ header instead of the C header, to allow for - in my opinion - a more pleasing coding style and architecture.
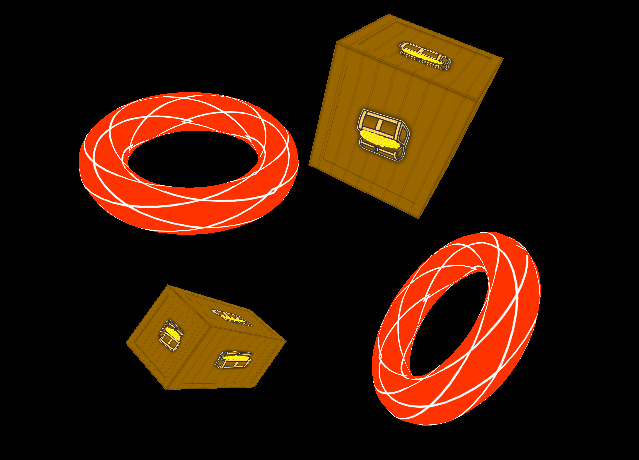
Although we have a working OpenGL renderer and have successfully loaded and displayed a 3D mesh, our approach is a tad rigid. We have so far hard coded our implementation directly into the OpenGLApplication class. This article will be long and is jam packed with refactoring and improvements including:
While this will be the final OpenGL based article before we delve into the Vulkan implementation, be sure to carefully follow through it to the end as some of the changes are quite significant.

Now that we have a 3D mesh rendering to our screen we will add texture mapping to start breathing a bit of life into it.
In this article we will cover:
SDL2_image to help us load image files for our texture mapping.assets code to load texture files from storage.
So here we are, 10 articles in and we are yet to see a 3D model on the screen. We spent valuable effort in part 9 to be able to load a model into memory, so let’s forge ahead and start rendering it.
This article will cover some of the basic steps we need to perform in order to take a bundle of vertices and indices - which we modelled as the ast::Mesh class - and hand them over to the graphics hardware to be rendered. Here’s what we will be doing:
ast::Mesh and generate an OpenGL flavoured mesh object which will use VBOs, then use the OpenGL mesh as the source for rendering.camera class that will contribute to the rendering pipeline which will configure where the virtual eye of our world should be.
Our trusty green screen hasn’t been particularly inspiring so far but its main purpose was to allow us to focus on the basic bare bones of our engine. If we had tried to setup our cross platform engine and tried to also load a 3D model and display it, the earlier parts in this series would have been (even more!) confusing. Now that the core bones of our engine are ready, we can begin loading and rendering 3D models.
This article will be fairly long because loading a 3D model actually requires us to introduce a number of new concepts and techniques into our code base. Specifically we will cover the following in this article:
assets into each platform and link them into the build pipeline for each platform.obj formatted file, parsing it into the appropriate data structures which can then be used as a rendering source.Note: The
GLMlibrary is not just for OpenGL, it can be used for any 3D math though it was originally designed to work well with the kinds of data structures typically needed to write OpenGL applications. In later articles you will see that it works just as well for our Vulkan implementation as well.

Now that we have onboarded all our platform targets we can start concentrating more on authoring our C++ application code. As hinted at in the previous article, the code we have written so far will get our app up and running, but some parts are actually a bit smelly.
The goals of this article are:
application class which knows how to run the main loop we made but doesn’t prescribe the graphics technology to use.application concept to model an OpenGL application - with a view that at a later point we would also have a Vulkan application.main.cpp class into an engine class, which will be responsible for resolving the correct application and running it.
In this article we are going to add in the Windows platform target to our existing workspace. This article almost never got written - I didn’t have a Windows machine that I used for development during most of the research for these articles. As I mentioned in part 1 of this series, in April 2019 I bought myself an Acer Predator Helios 500 Windows gaming laptop.
I bought it for a few reasons:
I still spend almost 100% of my day job using a Mac, and most of my home development is still done on my MacBook Air 2012, but I am really enjoying having the Helios 500 handy for not only gaming but as a very capable alternate development platform. And let’s face it - Visual Studio on Windows is pretty much the gold standard in terms of C++ development IDEs, so I very much had this series of articles in mind when deciding to buy the Windows machine.
The purpose of that ramble was to highlight that I would probably never have folded in the Windows platform into these articles if I hadn’t bought my Windows laptop. So let’s jump in and get our engine running on Windows!!
In this article we are going to add in the Emscripten platform target to our existing workspace. This will give us a way to run our application within a WebGL compatible browser.
For me this is one of the coolest technologies I got to play with while writing this series of articles. Many (many!) years ago I was a professional multimedia developer and spent a great deal of my time developing rich browser applications using Adobe Flash and have also published mobile applications developed with Adobe AIR.
Around the same time that Steve Jobs killed off Flash (yeah he did) I shifted gears and gave up being a multimedia developer and instead became a mobile app developer with more of a focus on business centric mobile apps. To see a modern technology like Emscripten that allows rich multimedia software to run in the browser again really impresses me and reminds me of my multimedia days.
Enough reminiscing though, let’s get into it. I would highly recommend spending a good amount of time reading the official Emscripten site: https://emscripten.org - the technology is truly remarkable and is a great use case of LLVM.
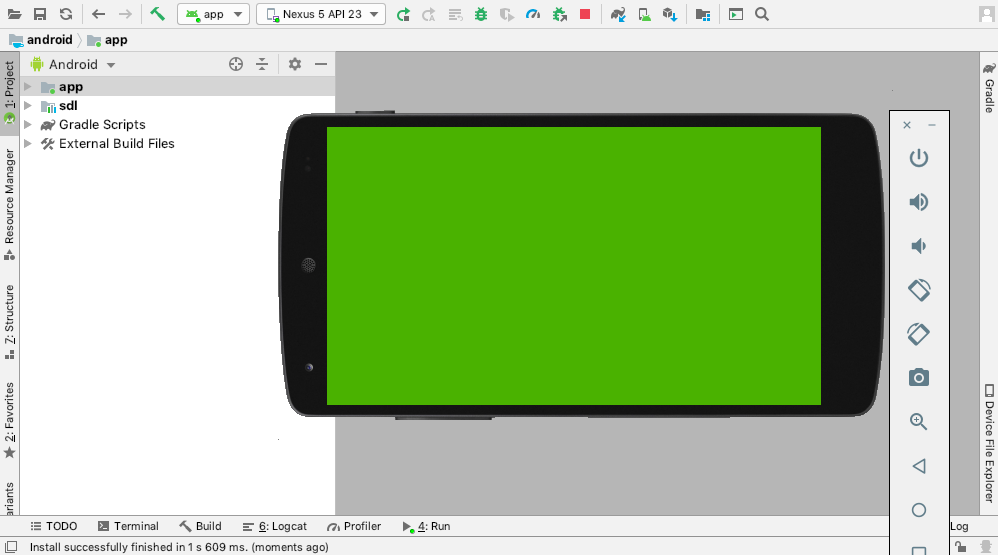
In this article we are going to add in the Android platform target to our existing workspace. To recap where we got to in our previous article we:
XcodeGen to automatically create the project.In this article, we will onboard our Android platform target, which will consist of:
Android app module.Android library module.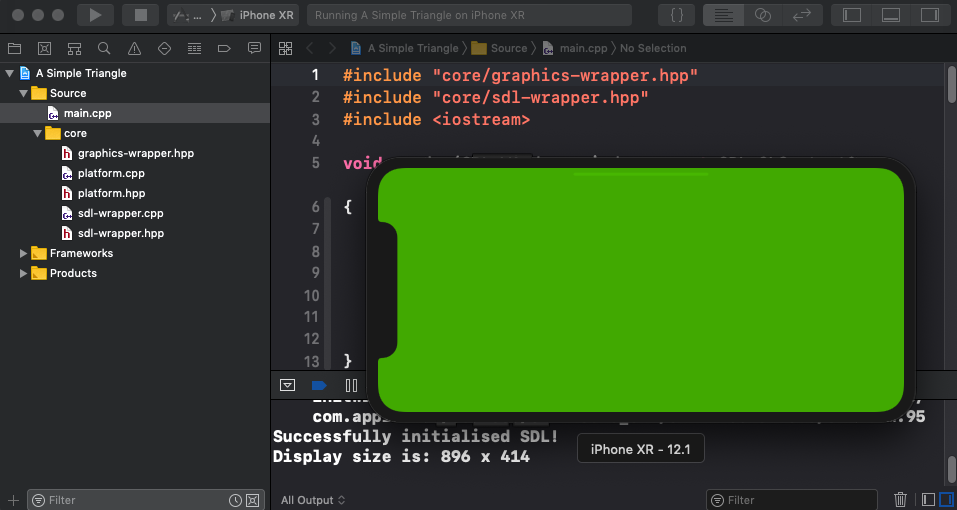
In this article we are going to add in the iOS platform target to our existing workspace. To recap where we got to in our previous article we:
XcodeGen to automatically create the project.The setup for an iOS application will have a few similarities to the MacOS setup. Specifically, we will be using XcodeGen again to automatically generate the iOS Xcode project - giving us the same advantages that were discussed in the MacOS setup article.
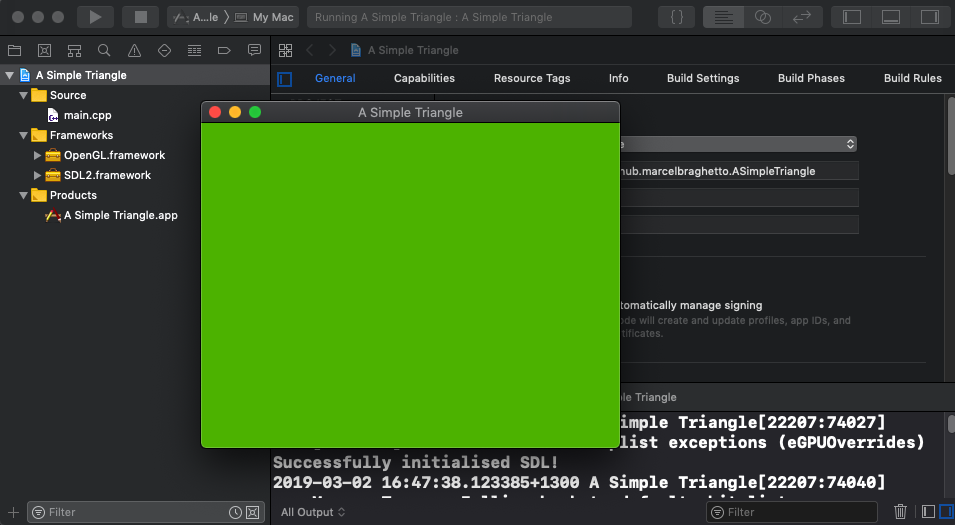
In this article we are going to add in the Mac Desktop platform target to our existing workspace. To recap where we got to in our previous article we:
To add the Mac Desktop platform target, we will build upon our existing workspace, continuing the theme of automating the setup scripts.
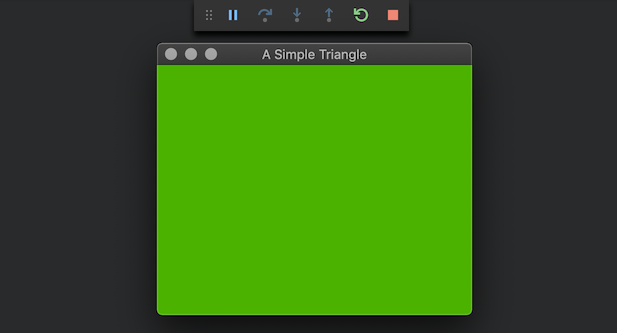
In this article we are going to start building the foundation of our engine.
Note: This article is quite long because we will be doing some automated foundational setup stuff before we start to actually write any code. The extra effort to automate our setup work will pay off when introducing the other platform targets later.
We will begin with our first target platform - a MacOS console application. We will use CMake as the build tool to define and compile our program using the Clang compiler that gets installed alongside Xcode (which is why we needed to install Xcode and its command line tools in the last article). The console application will give us a nice quick application to do our development and iteration on without being burdened with having to deploy to a device such as a phone or simulator.

Welcome to the first article in my series A Simple Triangle, or AST for short, which is the brain dump of my learning journey into how to author a very simple cross platform graphics engine using C++ and a variety of software toolkits. I picked the name A Simple Triangle because triangles are one of the fundamental structures that we end up rendering in a graphics system.
By the end of this series I hope to have documented my knowledge about how to do the following things:

Get the source for this example here
If you’d like to try it out on your device:
I wanted to play around with AIDL - Android Interface Definition Language to test out how it can be used to communicate between two (or more I guess) Android processes at run time.
I found that there is more than one way to do Inter Process Communication (IPC) on Android, but I wanted to focus on the scenario of two completely different APKs talking to each other, via a contract defined using AIDL.

If you’d like to try it out on your device:
Download and install Permutations-Playground.apk
In my Internet travels, I came across a coding question that looks something like this:
Find the number of permutations of string A in string B
The idea is that the characters in the search term are compared in every permutation to the characters in the search data to identify how many instances can be found.
Although it seems kind of simple, the brute force approach of looping through every permutation of the search term for every permutation of each frame of data in the search data ends up being O(n!) factorial complexity which is pretty much useless for anything.
I can’t recall the exact place where I originally found this question - it might have come from Career Cup or something.
Anyway, it looked like an interesting problem to try and solve - in particular to try out different approaches to see which Java data structures work OK and which ones seemd to be able to do the calculations the fastest.

Get the source for this example here
Often when building Android apps we need to find a way to apply different configuration settings depending on the type of build. For example, a development build might need to point to a development server, or a production build might need to prevent any configuration at all.
There are myriad of ways to achieve this, but I thought I’d build on an earlier post regarding deep linking to demonstrate how to have a companion configuration app or web page which is capable of launching the main application with a given state.
Our companion launcher app will be known as Configula because it will have the ability to infect our debug application behaviour - you know - just like vampires can, however we’ll also walk through how to put a silver cross on our release builds to repel Configula…

If you’d like to try it out on your device:
Download and install Treasure-Crab.apk
This post continues on from my Dijkstra’s Algorithm - Part 1 post. In this part we will put together a basic Android app to visualize the pathfinding. Let’s call the app Treasure Crab. The goals for the app are to:
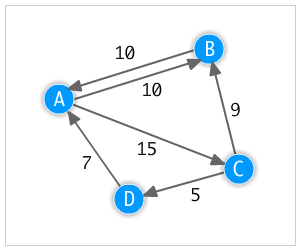
So there’s probably a bunch of ways to do path finding but I wanted to try out Dijkstra’s algorithm using a basic graph structure.
In this post I’ll show examples of:
I’ll walk through some basic building blocks for making a graph in general as well.
Get the source for this example here
A number of blog posts in this site include sample code that I am writing into an Android app as kind of a kitchen sink sandbox app to demonstrate how the code runs.
I hadn’t tried using deep links before and I thought it would be really cool if I could have HTML links in my blog content that could open my Android apps directly to code samples related to my blog posts.